Har du noen guilty pleasures blant julemusikk? Litt pinlig å bli rørt av, liksom? Eller blir du irritert av julemusikken som spilles i bakgrunnen i butikkene, men kommer i akkurat den rette julestemninga av akkurat den rette juleplata på akkurat det rette tidspunktet?
I dag skrev jeg et blogginnlegg om dette til Humanistisk Fakultet ved #NTNU sin adventskalender.
Og for dere som ikke følger den adventskalenderen, så kan dere lese det her:
Hvorfor er ikke desember med når Spotify summerer opp hvilken musikk folk har hørt på det siste året?
Fordi da får de ikke statistikken ut i tide til at folk vil dele på sosiale medier
Fordi folk hører mest på julemusikk i desember
Fordi Spotify ikke vil oppfordre til mer julemusikk enn strengt tatt nødvendig
Julemusikk er så omfattende (og likedan) i store deler av verden, at når Spotify lager sine årlige statistikker spesialsydd til hver enkelt av oss, om hvor mange minutter du lyttet til musikk i året som gikk, hva som var musikken og artistene du hørte mest på osv, så er ikke engang desember med. De regner med at det vil forvrenge årets statistikk så mye at den da blir ubrukelig. Da hører vi nemlig på julemusikk. Punktum. Og der spiller personlig smak mindre rolle enn resten av året.
(Riktig svar er altså alternativ 2.)
Les mer om dette og hva som er hemmeligheten til White Christmas i musikkforsker Nora B. Kulset sitt blogginnlegg om julemusikk.
(Klikk på ordet «blogginnlegg» i setningen over og du får lese hele innlegget mitt. Du kommer nok til å kjenne deg igjen…)
Og til deg som vil lese videre om det jeg skriver om, så er kildene følgende:
Nordengen, H. (2016). Julemusikk og nostalgi. Bacheloroppgave ved NTNU Institutt for musikk. http://www.ballade.no/sak/julemusikk-nostalgi-og-kulde/
North, A. og D. Hargreaves. (1996). Responses to Music in Aerobic Exercise and Yogic Relaxation Classes. British Journal of Psychology, 87(4), 347–356
Rentfrow, P., J. MacDonald. (2010). Preference, Personality and Emotion, I Juslin, P. og J. Sloboda (red.) Handbook of Music and Emotion. (kpt 24). Oxford University Press: Oxford.
Er språkgrupper bra? Er språktesting lurt? Hvordan skal vil sørge for at alle lærer seg norsk mens de går i norsk barnehage? Øve i små grupper? Teste om de lærer noe? TRAS? Aktivt ordforråd? Passivt ordforråd? Hva med de sjenerte? Er de bare tause eller kan de masse? Hva betyr det at de ikke vil snakke når vi utfører språktesten? Og hva med de sinte? Hvorfor er de så utagerende? Og hvem har språkvansker, og hvem er bare treg fordi norsk er deres tredje språk? Hva skal vi gjøre? Hvem skal vi høre på? Politikerene? Torbjørn Røe Isaksen?
Sukk.
Barnehageforsker Anne Greve ved Høgskolen i Oslo og Akershus, hadde denne uka et fra mitt ståsted glimrende innlegg i denne debatten (eller i dette dilemmaet, som man vel også kan kalle det). Hun understreker at LEK er det sentrale for små barn, og at de i leken får oppleve glede og samhold, tilhørighet og det å bli sett. I slike settinger kan et lite barn best tilegne seg et nytt språk, sier hun, og ikke ved et økt fokus på læring, slik Torbjørn Røe Isaksen ønsker. (Les hele innlegget her.)
Men dette er det ikke alle som er enige i. Ganske raskt kom Monica Melby-Lervåg fra Institutt for spesialpedagogikk ved UiO på banen og viste til sine nyeste studier hvor pedagogiske læringstiltak som språkgrupper derimot viste seg å ha stor effekt på barnas språktilegnelse. Hun kritiserte Anne Greves innspill som «anekdotisk» (en ikke-dokumentert historie) og kaller barnehagenorges opprør mot mindre tid til lek og mer fokus på læring i barnehagen, for en «empiriløs reproduksjon av ‘urban myths’». (Les hele innlegget fra Læringsbloggen.no her.)
At studien hun viste til kun ble utført på barn som var 5 år – altså året før skolestart, og at den dermed ikke kan sies å være gyldig for barnehagebarn som sådan – fikk jeg oppgitt av Melby-Lervåg på direkte forespørsel. Riktignok har de i studien angitt gjennomsnittsalder til 5,5 år, men samtidig avviser Melby-Lervåg funn fra Golberg et al. (2008) som peker på at barn under 5 år har svært dårlig utbytte av å få «skoleliknende» språkstimulering sammenliknet med barna over 5 år. Hvorfor avviser Melby-Lervåg andre liknende funn? Vil hun at sin egen studie skal framstå som den har større overføringsverdi enn den egentlig har? Prøver hun å gjøre seg populær blant politikerne som sitter på pengesekken? Gjett om Røe Isaksen blir glad for slike funn som Melby-Lervåg produserer.
Skjermdump fra Læringsbloggen.no
Selvsagt vil det bedre barns språktilegnelse når man setter inn ekstra ressurser (altså pedagoger) som er spesialtrent i språkstimulering. Hallo. Jeg er nesten fristet til å si «er det dette skattepengene mine brukes til?», men jeg sier det ikke. Men det kan ikke sies å være et oppsiktsvekkende funn. Argumentasjonen ut fra funnet kunne da også ha vært «bemanningsnorm» i stedet for «språknorm». Det hjelper med flere ansatte, flere pedagoger, flere med god utdannelse – som også blant annet kan legge til rette for en god og trygg hverdag for alle hvor lek kan foregå i trygge rammer, uavhengig av sosial og kulturell kapital. I stedet velger Melby-Lervåg å kritisere oss som fremmer lek som inngangsport til erfaring og dannelse for et menneske i starten av livet og roper heller om en mer læringsbasert barnehagehverdag. Hun gjør sågar narr av måten Anne Greves innspill er presentert på: «Hadde dette skjedd innenfor for eksempel medisin eller naturvitenskap?» Nei, men er det dét vi innen humaniora og samfunnsvitenskap skal sammenlikne oss med for å drive med gyldig forskningsformidling til folket?
Hadde dette skjedd innenfor for eksempel medisin eller naturvitenskap?
Jeg har også forsket på språktilegnelse hos minoritetsspråklige barn i barnehage. Jeg har sett på de barna som IKKE kommer seg inn i leken og samspillet (til tross for at de er med i språkgrupper). Jeg har sett på hva økt bruk av sang i hverdagen kan bidra med sosialt for disse barna. Resultatene peker tydelig i retning av at et felles sangrepertoar hjelper barna med å bryte inn i leken, og dermed kommer de også raskere i gang med språket (Kulset, 2015). Dette er kvalitativ forskning, og som en nyhet til Røe Isaksen og hans folk (muligens inkludert Melby-Lervåg) kan jeg opplyse om at kvalitativ forskning oppsto som en motreaksjon til kvantitativ forskning nettopp fordi sistnevnte ikke maktet å fange opp kompleksiteten i situasjonen til ulike former for marginaliserte grupper. Alt kan ikke bevises med statistikk: det er som kjent også mange sannheter med sterke modifikasjoner som kan frambringes på denne måten.
Hvor vil jeg hen med dette? Forskning skal være gjennomsiktig og redelig. Hva vil Melby-Lervåg med sine utspill? Ha rett? Når Melby-Lervåg angriper Anne Greve og kaller hennes utspill (og forskning) om viktigheten av lek, samhold, tilhørighet og glede for «anekdotisk», for deretter å forsvare dette med å vise til sin egen studie som motbevis, en kvantitativ studie hvor 5-åringer ble bedre i språk etter å ha blitt stimulert både i små grupper og én og én av spesialtrente pedagoger, og aldeles uten å samtidig argumentere (hovedsakelig) for økt pedagogtetthet – da forstår jeg ikke at hun er ute etter annet enn å plise bevilgende myndigheter for å sikre sin plassering i tildelinger om forskningsmidler.
Slik forskning kan jeg ikke annet enn stille et stort spørsmålstegn ved.
Og i stedet for å gjøre narr av andre, kan man ikke heller slå seg sammen og samarbeide til beste for barna? Og for å finne ut hva dét er, så må man nok dessverre også gå kvalitativt til verks. Selv om Torbjørn Røe Isaksen liker positivistiske bevis. Det er det dessverre umulig å frambringe når det gjelder mennesker og deres livsverden. Også for Melby-Lervåg.
Gåsehud er noe vi får når vi er kalde eller redde – men hvorfor får vi gåsehud ved sterke musikkopplevelser?
Gåsehud kommer fra tiden da vi hadde mer pels på kroppen enn nå. At hårene reiste seg kunne enten hjelpe oss med å holde varmen, eller det kunne få oss til å se større ut enn vi egentlig var, og dermed kunne vi skremme bort en fiende som nærmet seg.
Det er adrenalin som får hårene til å reise seg og framkalle gåsehud. Og det kan vi jo framkalle på så mange ulike vis:
Men hva har dette med den gåsehuden vi kan få av å høre på denne dama? Eller den gåsehuden hun selv og andre musikere kan oppleve når man lager musikk?
Tone Åse i aksjon med bandet BOL & SNAH
For å finne ut av det, må vi gå til livets fire F’er:
Fight, Flight, Feed, Breed
(jada, den siste der er jo ikke en F, men alle skjønner at man ikke kan skrive den F’en. Derfor passer det bedre med et ord som rimer på feed)
Fight, flight, feed or breed
Hjernen belønner oss for adferd som fremmer overlevelse, og de fire F’er dekker de mest grunnleggende faktorene for å sikre oss et så langt liv som mulig. Hver gang vi gjør noen av disse F’ene, sender hjernen signaler til belønningssystemet. Belønningen blir lagret i hukommelsen og skal tjene som en forsterker for at vi skal gjenta oppførselen. Dette var superbra! Gjør mer av dette!
Og nå snakker vi ikke om adrenalin lenger, men om DOPAMIN, kroppens eget kokain. Dopamin er belønningssystemets utbetaling, og det gir oss rett og slett en rus. Vi føler oss høye, avslappede, lykkelige – kort sagt svært fornøyde. Og så vil vi gjenta det som ga oss denne belønningen. Ett av hovedmålene for hjernen er faktisk å forutsi belønnende hendelser. Hjernen er en dopaminjunkie som hele tida prøver å tolke og gjette seg fram etter noe å kjenne igjen, ett eller annet som kan gi oss et rush av belønningsrus.
Den kjemiske strukturen til dopamin
Menneskehjernen er faktisk en kløpper på å kjenne igjen mønstre. Evolusjonært sett er dette en praktisk vane å ha: å gjøre gode forutsigelser er avgjørende for å overleve. Og derfor fungerer hjernen vår slik som dette:
Forventning er et viktig stikkord her. Det å kjenne igjen et mønster og vite hva som nå skal skje, bygger opp til en forventning hos oss som lett ender i et lite adrenalinkick av bankende hjerte, skjelvende hender eller sommerfugler i magen.
Men så var det musikken da.
Musikk stimulerer belønningssystemet i hjernen som fører til at hjernen oversvømmes av dopamin.
Når vi lytter til musikk, eller når vi selv lager musikk, så kan vi oppleve voldsomme rush av gåsehud og ilinger nedover ryggen. Hva har dette med livets fire F’er å gjøre?
Jo, det handler om hjernens dopamindrevne gjettelek. Forventningen om mønsteret som skal gjentas, eller på opplevelsen av et nytt mønster, gjør at hjernen så og si holder pusten. Det merkelige er at dopaminnivået kan toppe seg flere sekunder før sangen du elsker når sitt spesielle øyeblikk. Det er fordi hjernen din er en god lytter – den forutsier stadig hva som kommer til å skje videre.
Men musikk er vanskelig. Den kan være uforutsigbar, erte hjernen vår og holde de gjettende dopaminutløserne på pinebenken. Og det er der gåsehuden kan komme inn. For når du endelig høre en etterlengtet akkord, sukker hjernen i dopaminoversvømt tilfredshet og – ahhh – du får frysninger. Jo større oppbygging, desto større er gåsehuden.
Og når alt dette skjer, så er det som om alle røde varsellamper lyser og uler og blinker oppe i hjernen. Inntrykkene som kommer inn er massive! Er de farlige, mon tro? Fight or flight? Når det så viser seg at denne over-kill’en av supersizede inntrykk slett ikke var farlige, så kommer det gode rushet i stedet for nødreaksjonen: gåsehuden blir av det behagelige slaget, og hjernen belønner oss for riktig reaksjon. Vi ble jo på vakt, vi passet på livet vårt, selv om det viste seg at det ikke var noe farlig.
Eller?
Er det på grunn av dette at hjernen aktiverer belønningssystemet og sender ut dopamin når vi lytter oppmerksomt til musikken?
Det nyfødte spedbarnet er helt avhengig av å snu ansiktet sitt mot lyden av et annet menneske. Slik sikrer det overlevelse. Dermed belønner hjernen spedbarnet hver gang det snur seg mot mor eller far som snakker. Var det her det hele startet? Er det her gåsehuden vi belønnes med når vi lytter til eller skaper musikk, egentlig kommer fra? I det helt grunnleggende behovet et nyfødt menneskebarn har til å bli tatt vare på og elsket av sine nærmeste?
Det vet vi rett og slett ikke. Ikke enda.
Det vi derimot vet er at 50% av befolkning opplever gåsehud når de lytter til musikk, og hele 90% av musikere opplever det samme. Så da er spørsmålet: ble de musikere fordi de har lettere for å ha sterke musikkopplevelser, eller har de sterkere musikkopplevelser fordi de er musikere?
Også et spørsmål for framtidig forskning.
Les mer:
Nagel, Kopiez, Grewe, & Altenmüller (2007). EMuJoy: Software for continuous measurement of perceived emotions in music. Behavior Research Methods, Vol.39 (2), s.283-290.
Salimpoor, Zald, Zatorre, Dagher & McIntosh (2015). Predictions and the brain: how musical sounds become rewarding. Trends in Cognitive Sciences, 19 (2), s. 86-91. doi:10.1016/j.tics.2014.12.001
Vuust & Kringelbach (2010). The Pleasure of Making Sense of Music. Interdisciplinary Science Reviews, 35 (2), s. 166-182. doi:10.1179/030801810×12723585301192
Zatorre (2015). Musical pleasure and reward: mechanisms and dysfunction. I E. Bigand, B. Tillmann, I. Peretz, R. J. Zatorre, L. Lopez, & M. Majno (red.), Neurosciences and Music V: Cognitive Stimulation and Rehabilitation (Vol. 1337, s. 202-211).
Zatorre & Salimpoor (2013). From perception to pleasure: Music and its neural substrates. Proceedings of the National Academy of Sciences of the United States of America, 110, s. 10430-10437. doi:10.1073/pnas.1301228110
I have finally decided to publish an English edited version of my study from 2012 (published in the yet-only-in-Norwegian book «Musikk og andrespråk» earlier this year by Universitetforlaget), and my most keen followers will be happy to see that I have included more on the OPERA-hypothesis than in the original study. (Little did I know in 2012 that Mr. Dr. Patel himself was on the same pathway as I was).
So here it is, a gift (hopefully), from me to you. Use it well and a lot (again hopefully).
Sist uke da jeg befant meg i én av mine forskningsbarnehager, observerte jeg to treåringer som kommuniserte problemfritt. Dette til tross for at de ikke snakket samme språk. Ingen av dem hadde norsk som morsmål, og selv om de så ut som tvillinger for meg (og kanskje også for hverandre – hvem vet om det er derfor de leker så godt sammen?) så snakket de heller ikke samme morsmål.
«Bada bada dido!» «Beidi! Didoba blidi!»
Slik hørtes de ut. Mens jeg filmet dem i en halvtime.
To kyndige scattere!
De to jentene hadde en komplisert lek. Den innebar blant annet at den ene av dem etterlyste en tredje jente som hadde gått for å leke et annet sted, at de sammen gikk for å finne henne (med meg på slep), at de sammen ga opp å få kontakt med henne (den ene tydeligvis mer ivrig på å returnere til utgangspunktet enn den andre), og på å bytte på å være baby i ei dukkevogn. Som også betydde at de måtte bli enige om når de skulle bytte, hjelpe hverandre inn og ut av dukkevogna, samt bli enige om den som trillet dukkevogna skulle ha på seg veske eller hatt – og hvor fort vogna skulle trilles. Det måtte være fort som i artig, men ikke som i skummelt. De var to små jazzmusikere i en fantastisk improvisasjon.
Dette fikk meg til å tenke på forskningen som pågår knyttet til musikere som improviserer. Det forskes både på improviserende jazzmusikere og rap-artister som driver med free style (som altså er improvisasjon). Jeg har her lyst til å snakke litt om forskningen knyttet til improviserende jazzmusikere siden det minnet meg mest om situasjonen med de to små jentene.
Charles Limb ved Johns Hopkins University School of Medicine i USA har sammen med andre forskere, skannet hjernen til jazzmusikere mens de improviserer. De har gjort studier både på musikere som improviserer solo, og som er i en improviserende dialog med andre medmusikere, nærmere bestemt det som kalles «trading fours» (to musikere bytter på å improvisere over fire takter hver).
Dr. Charles Limb
Det de fant etter én times jamming inne i fMRI-maskinen, var ganske fascinerende. Begge de to områdene som er mest kjent for språkproduksjon, fikk økt blodtilførsel. Med andre ord: de var aktive som når vi snakker med noen. Disse to områdene knyttes til både produksjon av språk (Broccas område) og oppfattelsen av språklig betydning og indre bildedannelse (Wernickes område).
For hjernen ser det altså ut som at det å improvisere en dialog via nonverbale lyder, er det samme som å snakke sammen. Ut fra disse resultatene, forskes det videre på ideen om at musikk og språk deler et syntaktisk system i hjernen, selv om det semantiske systemet nødvendigvis må være ulikt (se f. eks. Aniruddh Patel).
De to små jentene i barnehagen improviserte dialogen sin, det ga dem mening, og de samhandlet ut fra meningen den ga dem. For å kunne gjøre dette så fritt og åpent, kunne de ikke være altfor selvkritiske – men de måtte likevel tilpasse seg den andres innspill i dialogen. De var tross alt ikke solister. Og her kommer et annet interessant moment inn fra forskningen til Charles Limb-gruppa. Hos musikerne som jammet alene inne i fMRI-skanneren, ble området for å overvåke seg selv skrudd av. Forskerne mener at dette henger sammen med at dersom du skal klare å være kreativ, så kan du ikke hele tiden vurdere om det du gjør vil bli feil eller ikke. MEN – når du skal være kreativ sammen med andre, når du skal klare å lage en dialog som også tar hensyn til den andres innspill, da blir området for selvovervåking skrudd på igjen.
Litt av konklusjonen her innebærer at dersom man lar denne selvovervåkingen ta overhånd, da dør kreativiteten. Og evnen til å improvisere. Kanskje kan et filmopptak med to små treåringer i ubekymret og perfekt timet babledialog tjene til inspirasjon?
Og hvorfor er dette nyttig for folk som verken er jazzmusikere eller treåringer som ikke snakker samme språk? Jo, fordi vi trenger nemlig også evnen til å improvisere når vi skal samhandle med andre mennesker i sosiale situasjoner som er litt annerledes enn det aller mest komfortable og trygge. Da vil vår evne til å bruke musikalske virkemidler kunne komme godt med. For i hjernen er det altså i stor grad samme sak.
Referanser:
Donnay GF, Rankin SK, Lopez-Gonzalez M, Jiradejvong P, Limb CJ (2014): Neural Substrates of Interactive Musical Improvisation: An fMRI Study of ‘Trading Fours’ in Jazz. PLoS ONE 9(2): e88665. doi:10.1371/journal.pone.0088665
Limb CJ, Braun AR (2008): Neural Substrates of Spontaneous Musical Performance: An fMRI Study of Jazz Improvisation. PLoS ONE 3(2): e1679. doi:10.1371/journal.pone.0001679@
Patel AD (2003): Language, music, syntax and the brain. Nature Neuroscience 6: 674–681.
Jeg har blitt oppfordret til å skrive litt om tonedøvhet. Én av mine venninner som jobber som musikklærer, fikk i høst en tonedøv elev. Eller var vedkommende virkelig tonedøv? Kunne min venninne kanskje hjelpe eleven å trene opp øret slik at det ble mulig å synge en sang med riktige toner?
Kan øret trenes opp til ikke å være tonedøvt?
Å være tonedøv – eller å ha amusia som den korrekte vitenskapelige betegnelsen er – er en nevrologisk forstyrrelse, eller en feilkobling i hjernen om du vil. Det er ulike former for tonedøvhet. Jeg kommer her til å fokusere på det vi kaller medfødt amusia.
4% av befolkningen er medfødt tonedøve.
Medfødt amusia er tonedøvhet man er født med, til forskjell fra den som kan bli påført senere i livet gjennom hjerneskader ved for eksempel slag, sykdom eller ulykker. Medfødt tonedøvhet er arvelig, og det er en livslang lidelse man ikke kan trene opp øret til å komme ut av.
(Selv om det altså er en skrekkelig tanke, så kan man miste evnen til å oppleve musikk etter for eksempel et slag. Akkurat som at man kan miste evnen til å snakke men fremdeles kunne synge, kan det også gå motsatt vei. Enkelte som før elsket musikk, kan etter et slag oppleve det kun som støy. Eller man kan nyte musikk som allerede finnes i minnene fra før slaget, men ikke klare å produsere eller oppleve ny musikk. Komponisten og pianisten Maurice Ravel (1875-1937) er et kjent eksempel på dette. Etter en bilulykke i 1932, kunne han ikke lengre skrive ned eller spille musikken han hadde i hodet sitt. Hjernen klarte ganske enkelt ikke å sende de riktige signalene på rett måte.)
Maurice Ravel
Hva tonedøvhet er, ligger i selve navnet vi har gitt det. Man er døv for tonehøyden. En defekt i hjernen gjør at man ikke har evnen til å gjenkjenne tonehøyde på samme måte som andre. Tonedøve kan ikke gjenkjenne en kjent melodi uten at de også får høre teksten, de kan ikke høre når de selv (eller andre) synger «falskt» eller «surt», og de viser ingen reaksjon på åpenbare dissonanser (toner som overhodet ikke passer inn) i musikken – en sensitivitet som finnes hos andre allerede i spedbarnsalderen.
Det som er spennende, er at de tonedøve likevel stort sett gjenkjenner musikken i det talte språket. Så lenge det er ord, kan de (med unntak) gjenkjenne prosodien – språkmelodien – i setninger. De kan dermed avgjøre om det stilles et spørsmål, og de kan forstå forskjellen i talte setninger som «heng han ikke, vent til jeg kommer» og «heng han, ikke vent til jeg kommer». De kan også gjenkjenne stemmefrekvenser, altså hvem sin stemme de hører, noe som også handler om å gjenkjenne tonehøyde. De vet forskjell på ulike dyrelyder og gjenkjenner andre normale lyder i nærmiljøet sitt. Hva er det som gjør at de ikke kan gjenkjenne tonene i en sang da?
Det som de tonedøve ser ut til å mangle, er evnen til å kartlegge tonene de hører. Vi musikere kaller det en skala. På ei linje er det noen toner vi plasserer høyt oppe, andre plasserer vi lengre nede. Dette gjør hjernen vår av seg selv. Hos de tonedøve fungerer ikke dette. En mulig forklaring er fordi arbeidsminnet – altså korttidshukommelsen – som er knyttet til akkurat dette, ikke eksisterer. Man kan si at white-board’en der vi andre noterer ned tonene vi hører, den er helt tom hele tida hos de tonedøve. Dermed blir det heller ingenting å arkivere i langstidsminnet.
Mangler hukommelse for musikk
Forsøk viser at det for tonedøve er bedre å synge sammen med andre enn å synge ut fra hukommelsen. De synger surt og feil uansett, men det er enda verre om de skal hente melodien fram fra egen hukommelse. Kanskje ikke så rart om det ikke finnes noe å huske?
Helt blankt!
Tonedøve har vanskeligheter med å høre endringer i tonehøyde som er mindre enn to semitoner. Det normale er å høre minst fire ganger så finkornet. Denne manglende evnen til å høre endringer i tonehøyden, fører deretter til en kjedereaksjon som går ut over flere områder. Dette kan for eksempel være å gjenkjenne puls eller å i det hele tatt bevege seg til musikk. For den tonedøve oppleves musikk som et fremmedspråk de ikke forstår noe som helst av.
Men enkelte tonedøve har faktisk 100% intakt rytmefølelse. En trommeslager kan dermed være tonedøv. Det finnes nemlig flere underkategorier av tonedøvhet. Akkurat som at enkelte tonedøve har rytmesansen in takt (bokstavelig talt…), så finnes det også noe som heter beat deaf. Dette er tonedøve som kan gjenkjenne tonehøyde men som ikke har noen oppfattelse av puls. I tillegg har man så vidt begynt å se på purely vocal tone deafness, altså at det kun er toner som synges man ikke klarer å skjelne tonehøyden på.
Men hva med min venninnes elev? Vil hun kunne trene opp vedkommende? Kanskje synger hun bare surt uten å være tonedøv? Én ting er å oppfatte tonehøyden. En annen ting er å reprodusere den, altså gjenta den. Fra å bare handle om det rent auditive, blir dermed også plutselig det motoriske planet koblet inn. Hvordan skal tonen gjenskapes? Hjernen må velge den rette motoriske planen, og deretter må den settes ut i livet. Også her ligger skjær i sjøen for de med medfødt tonedøvhet. Det er også her vi kan finne de som kalles poor pitch singers, altså de som bare synger rimelig falskt, men som ikke er helt tonedøve. Ca 10-20 % av befolkningen i et vestlig land, faller inn under kategorien som «sursangere». Her er det nok mange som faller for fristelsen å omtale seg selv (eller bli omtalt som) tonedøv. Det er man altså ikke. Derimot kan det hende man har rusk i apparatet som går fra det å høre tonen (det kan også gjelde å høre sangen i hodet sitt), via å mobilisere den rette motorplanen, at denne planen skal utføres på riktig vis, og at tonen deretter skal komme ut i riktig form. Her kan det godt være at det hjelper dersom man synger mer, men da er det som sagt mye nyttigere å synge sammen med andre enn å skulle synge alene.
Isabelle Peretz
Og ja, det finnes en test for å fastslå om noen er tonedøv eller ikke. Isabelle Peretz ved Brain, Music, and Sound Research (BRAMS) på Universitetet i Montreal, Canada, er en av de fremste forskerne på amusia. Hun utviklet i 2003 The Montreal Battery of Evaluation of Amusia (MBEA) sammen med Anne Sophie Champod og Krista Hyde. Hun arbeider nå for å lage en online-test som skal gi like trygge resultater som MBEA. Det er altså bare å google i vei.
Amusia er et stort og spennende felt. Og ved å forske på dette, lærer man mer om hvordan hjernen fungerer. Ved å se på de som ikke klarer å motta og behandle musikk som andre, finner man også ut hvilke områder i hjernen som er berørt og hvilke områder som likevel fungerer normalt. I forhold til slagpasienter og sykdommer som rammer hjernen, er dette avgjørende.
Hva er så det vi kaller «brummere»? Jeg overlater den diskusjonen til dere!
Litteratur:
Hutchins, Sean, & Isabelle Peretz. (2010). Perception and action in singing. Progress in brain research, vol 191.
Peretz, Isabelle m. fl. (2008). On-line identification of congenital amusia. Music Perception, 25(4).
Peretz, Isabelle m. fl. (2002). Congenital amusia: A disorder of fine-grained pitch discrimination. Neuron, 33(2).
Phillips-Silver, J. m. fl. (2013). Amusic does not mean unmusical: Beat perception and synchronization ability despite pitch deafness. Cognitive Neuropsychology, 30(5)
Tremblay-Champoux, A. m. fl. (2010). Singing proficiency in congenital amusia: Imitation helps. Cognitive Neuropsychology, 27(6)
Puh, nå er det lenge siden forrige blogg-innlegg. Å være doktorgradsstipendiat innebærer enkelte perioder med så mye mentalt stress at jeg er glad jeg ikke visste om det på forhånd.
Men nok om det. Noe av det jeg har brukt tida mi på etter jul, er å lese om hvordan musikkaktiviteter som for eksempel sang, fremmer vår evne til å samarbeide. Vår sosiale kompetanse øker med andre ord – noe å bite seg merke i for de som har fjernet musikkfaget fra utdanningen av nye pedagoger?…
Foto: Nora B. Kulset
For 30 år siden undersøkte Anat Anshel og David A. Kipper om det å synge sammen ville forsterke deltakernes samarbeidsevne og tillit til hverandre. De hadde 96 menn i alderen 22–41 år som ble delt i fire grupper. Faktorene var musikk og ikke-musikk vs. aktiv og passiv. Dette ga dem fire muligheter: aktiv med musikk (sang), passiv med musikk (lytte til innspilling av samme sanger), aktiv med ikke-musikk (diktlesing) og passiv med ikke-musikk (se på en dokumentarfilm).
Soweto Gospel Choir
Alle aktiviteter varte ca én time. Deretter fikk deltakerne to oppgaver. Den ene oppgaven var å svare på The Giffin-Trust-Differential spørreskjemaet. Dette består av en liste med adjektiver som rangeres på en poengskala fra 1–7. Hver deltaker skulle rangere én av de andre ut fra førsteinntrykket de hadde fått av vedkommende. Høye rangeringer (som 5, 6 og 7) betyr en mer positiv og tillitsfull vurdering.
Den neste oppgaven måtte utføres i par og besto av The Prisoner’s Dilemma game. Her måles samarbeidsevnen (og samarbeidsviljen) samt det motsatte: konkurranseinstinktet for å vinne på egne vegne. Dette er en enkel liste som handler om å velge mellom fargen rød eller blå på 30 gjenstander. Når begge så sammenlikner hva de har valgt, regnes poengene ut på følgende måte: Om begge har valgt blå, får begge tre poeng. Om begge har valgt rød, får de bare ett poeng. Dersom den ene parten har valgt rød og den andre blå, får den som har valgt rød fem poeng, mens den som har valgt blå får null poeng. Dette er regler spillerne blir forklart på forhånd. Det lønner seg altså for egen vinnings skyld å alltid velge rød – men for å samle mest mulig poeng også for partneren, lønner det seg å velge blå. Ingen kommunikasjon eller «lurkikking» var tillatt under utfylling av skjemaet.
Fra nrk.no
Nå ligger det vel i kortene at det var gruppa som sang aktivt som gikk av med seieren i begge tester. «Tillit og samarbeid er grunnleggende faktorer for å skape samhørighet og gruppetilhørighet – noe som er en nødvendig ingrediens for å få folk til å fungere sammen i det hele tatt», slår forfatterne fast. Og én av bidragsyterne til dette er altså det å drive aktivt med musikk sammen. Mere allsang gir ganske enkelt et bedre sosialt miljø i følge denne rapporten. Ingen bombe for mange av oss, men likevel forsvinner musikkfaget. Og dette er 30 år gamle resultater. På tide å løfte de fram igjen?
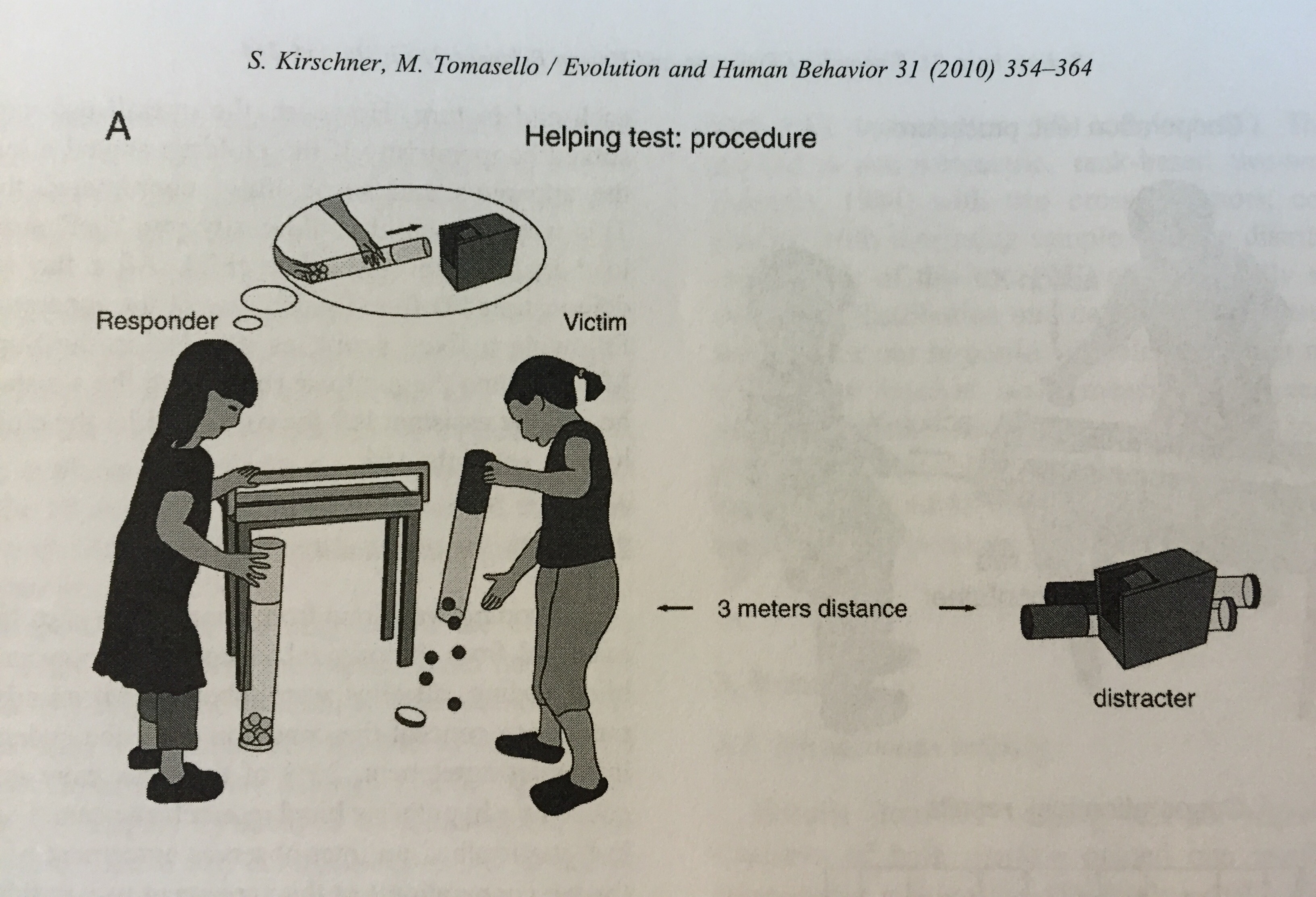
I 2010 ville Sebastian Kirschner og Michael Tomasello undersøke om dette også gjaldt for små barn. De designet et eksperiment hvor 96 fire-åringer ble gitt to ulike aktiviteter som de deltok på i par. Begge gruppene deltok i en lek om frosker og fisker, men i den ene gruppa var det også innbakt sang og rytmiske leker. Hver «leksjon» varte i 20 minutter og besto av fire deler: (1) arrangert lek (2) eksperiment A (3) arrangert lek og (4) eksperiment B. Den arrangerte leken besto av voksenregissert lek med eller uten musikalske elementer. Eksperimentene besto av to oppgaver knyttet til leken som barna skulle utføre (mens de trodde at de fremdeles var i leken). Disse eksperimentene målte barnas prososiale evner, det vil si oppførsel som er positiv, konstruktiv og hjelpende.
Illustrasjon fra den omtalte artikkelen.
Slike empatiske eksepriment består av at den ene har et uhell (som er forhåndsfikset uten at noen vet det), og at man deretter ser om den andre hjelper til eller fortsetter videre for egen vinnings skyld.
Man må nesten si at det er urovekkende hvor mye mer barna som hadde drevet med musikk i aktivitene, hjalp hverandre enn de som ikke hadde musikk inkludert i sin lek. Spesielt for guttene slår dette voldsomt ut. Gutter som ikke hadde hatt musikk, hjalp omtrent ikke «offeret» i det hele tatt. Etter musikkaktiviteten firedobles guttenes aktive hjelp. Dette er voldsomme resultater som vi ganske enkelt må ta innover oss slik at vi slutter å se på musikk som et unødvendig «kosefag».
Felles musisering skaper en gruppefølelse som gjør at vi blir bedre i stand til å ta vare på hverandre.
Referanser:
Anshel, Anat og David A. Kipper: The Influence of Group Singing on Trust and Cooperation. Journal of Music Therapy, vol 25, 1988.
Kirschner, Sebastian og Michael Tomasello: Joint music making promotes prosocial behavior in 4-year-old children. Evolution and Human Behavior, 31, 2010.
«Lærere melder om økt konfliktnivå i skolen på grunn av elevenes manglende evne til å lese kroppsspråk». Oj!
«Derfor bruker skolen tid på å lære elevene forskjellen mellom å snakke i det virkelige liv og på nettet». Oj!
Skoletimer i hvordan man skal kommunisere med andre mens man også tyder ansiktsuttrykk og stemmeleie! Dette melder NRK Rogaland i dag.
For kort tid siden ville vi ha sagt at de som mangler evnen til dette, har bemerkelsesverdig lav sosial intelligens. Muligens en diagnose. Er vår evne til å tolke andre mennesker virkelig på vei til å bli en utdøende ferdighet?
Professor Steven Mithen
Det å uten ord kunne føle og vise egne emosjoner, og å kunne tolke andres på samme måte, er viktigere enn vi kanskje umiddelbart tenker på. (Og derfor er det heller ikke særlig lurt å lamme ansiktsmuskulaturen med botox). Steven Mithen, professor i arkeologi og forsker på utviklingen av menneskeslekten homo, mener bestemt at det å kunne se andres følelser, er avgjørende for at man i det hele tatt skal kunne leve sammen. Han forteller i boka «The Singing Neanderthals» om hvordan neandertalerne nødvendigvis må ha hatt det samme spekteret av følelser som også det moderne mennesket har – sinne, frykt, skyld, overraskelse, avsky, tristhet, forakt, sorg og glede – for hvis de ikke hadde hatt det, ville de ikke ha klart å leve sammen i slike store og komplekse grupper som de gjorde. De ville rett og slett ikke ha stolt på hverandre og derfor i stedet ha tatt livet av så mange som mulig. Og vi vet jo at det ikke var derfor neandertalerne døde ut.
The Singing Neanderthals – the Origins of Music, Language, Mind, and Body
Ansiktsuttrykkene for disse sju følelsene – sinne, frykt, skyld, overraskelse, avsky, tristhet, forakt, sorg og glede – tolkes likt i alle kulturer. Det forteller oss noe om hvor biologisk dette ligger nedfelt i mennesket som art. Hvis denne evnen nå ser ut til å forsvinne, må vi stoppe opp og spørre oss selv om hva det er vi holder på med.
Èn ting vi kan gjøre er å peke med en streng og stygg finger mot diverse skjermaktiviteter, det nye som har kommet inn i livene våre. Men en annen ting vi kan gjøre, er å spørre om hva det er vi har tatt bort i det siste. Hva er det som har forsvunnet ut av skolen som bidrar til at den sosiale kompetansen går nedover?
Om vi går tilbake til neandertalerne, eller til de første homo, så hadde de rett og slett verken hjerne eller fysiologi til å lage ord slik som vi kan i dag. De kommuniserte følelsene sine ved hjelp av ansiktsuttrykk og vokaliseringer. De brukte stemmen sin til å fortelle, men uten ord. For to millioner år siden var det altså ikke særlig langt mellom sang og språk. Det var slik vi bl.a. knyttet bånd, beskyttet oss, markerte oss og sørget for at andre visste at vi var til å stole på.
I dag blir vi også på «mystisk» vis utrolig tilfredse av å synge sammen med andre. Vi får en opplevelse av å koble oss på – både på oss selv og de andre. Vi får en følelse av fellesskap. Og det er kanskje ikke så rart når vi tenker på at dypt inne i vår biologiske arkeologi, er dette det samme som å bekrefte nettopp samholdet i gjengen. En kommunikasjon uten ord.
Når sang og musikk tas bort fra skolen, tar vi også bort barns mulighet til å utvikle dette sosiale språket. Vi tar bort muligheten deres til å oppleve tilhørighet og samhørighet via det å synge (og evt spille) sammen. Om man må ha egne timer i kommunikasjonskompetanse, da er det på tide å satse tungt på den aller mest grunnleggende kommunikasjonskompetansen i biologien: sang og musisering
Musikk er ikke et valgfag. Musikk er et dannelsesfag.













 Forventning er et viktig stikkord her. Det å kjenne igjen et mønster og vite hva som nå skal skje, bygger opp til en forventning hos oss som lett ender i et lite adrenalinkick av bankende hjerte, skjelvende hender eller sommerfugler i magen.
Forventning er et viktig stikkord her. Det å kjenne igjen et mønster og vite hva som nå skal skje, bygger opp til en forventning hos oss som lett ender i et lite adrenalinkick av bankende hjerte, skjelvende hender eller sommerfugler i magen.